jonathanjuliani
Estrutura de Dados e Algoritmos - Um Resumo dos Mais Utilizados
Resumo prático das estruturas de dados e algoritmos mais usados em JavaScript/Node.js — com exemplos e links para aprofundar cada tema.
Escolher a estrutura errada para um problema — array onde precisava de hash table, busca linear onde a lista já estava ordenada — costuma virar bug lento que só aparece com volume de dados. Este post é o mapa: quinze estruturas e algoritmos que mais aparecem em JavaScript/Node.js, com critério de quando usar cada um e link para implementação na série.
O que você vai aprender:
- O que são e pra que servem Arrays, Listas Ligadas, Pilhas, Filas, Árvores e Grafos
- Hash Tables, Heaps, Filas de Prioridade, Maps e Sets — onde cada um brilha
- Busca Binária, Árvores de Busca Binária, Tries e Algoritmos de Grafos — quando usar
- Algoritmos de Ordenação (BubbleSort, QuickSort, MergeSort) — como diferenciar
- Em qual cenário do dia a dia cada estrutura aparece — com exemplos práticos
Pré-requisitos: familiaridade com programação básica — o que é uma variável, uma função e um array. Não é necessário ter experiência prévia com estruturas de dados.
Critério desta lista: estruturas que aparecem em entrevistas, em código de produção Node.js e nos episódios seguintes desta série — com exemplo mínimo e link para aprofundar. Não é catálogo acadêmico completo.
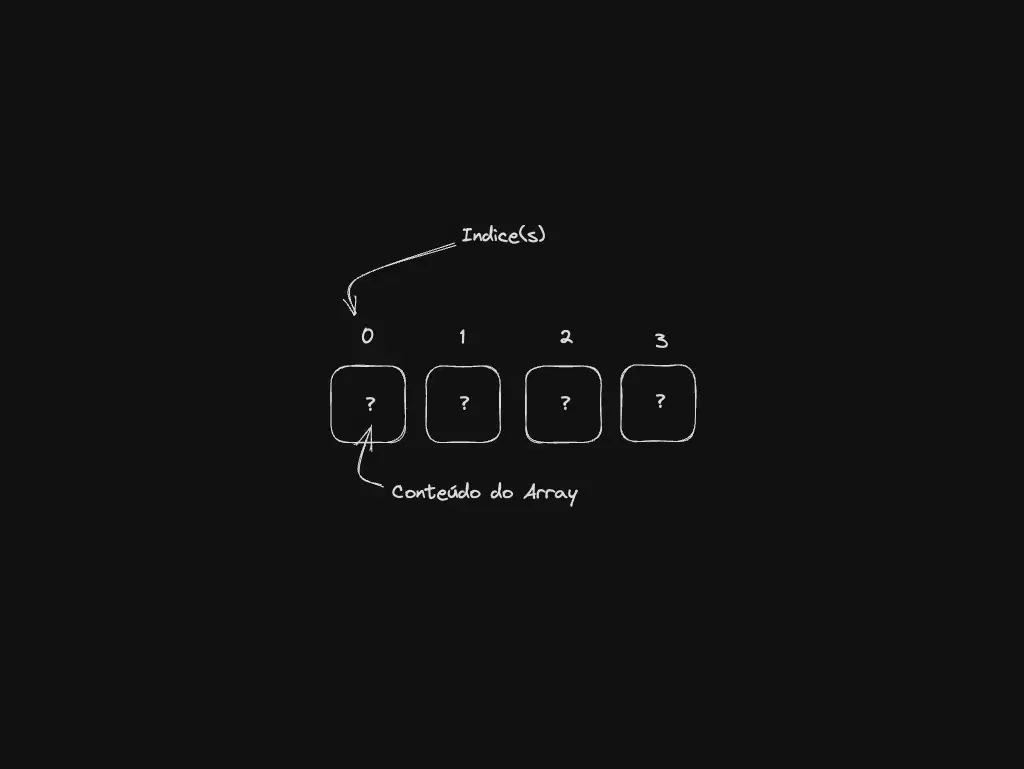
Arrays: a estrutura que você já usa todo dia
Arrays são como listas que guardam elementos em sequência, facilitando guardar e acessar dados rapidamente por meio de índices. São super comuns na programação para várias necessidades, como listas de tarefas, compras ou produtos.
Basicamente, sempre que você tem uma coleção de itens organizados, provavelmente está usando um array.
Melhor para: acesso por índice, iteração sequencial, listas que cabem na memória sem inserir no meio o tempo todo.
Quando não usar: inserções/remoções frequentes no meio de coleções enormes — linked list costuma compensar.
Aprofundar: Implementando Arrays com Node.js e JavaScript
Linked lists: flexibilidade sem remexer no array inteiro
Listas ligadas são como um trem de dados onde cada vagão, ou “nó”, não só carrega uma informação, mas também indica qual é o próximo vagão na linha.
Diferente dos arrays, cada elemento é ligado ao próximo, facilitando adicionar ou remover itens sem mexer no resto da “linha”. Nas listas duplamente ligadas, cada nó conhece tanto o seu próximo quanto o anterior, tornando ainda mais fácil navegar para frente e para trás. Isso é ótimo para tarefas como inserções e exclusões rápidas.
Um exemplo prático é o histórico do navegador, onde cada página visitada é um nó, permitindo ir e voltar facilmente entre as páginas. Lista ligada:

Lista duplamente ligada:

Melhor para: histórico de navegação, filas de edição, inserir/remover no meio sem deslocar o array todo.
Quando não usar: quando você precisa de acesso aleatório por índice em O(1) — array ganha.
Aprofundar: Implementando Listas Ligadas
Pilhas (stacks): LIFO no undo e na call stack
Stacks, ou pilhas, seguem a regra de “último a entrar, primeiro a sair” (LIFO [last in, first out]) aqui faz sentido a famosa frase: "os últimos serão os primeiros"). Pilhas são ideais para controlar sequências de ações, como históricos, onde o mais recente é sempre o primeiro a ser acessado ou algo como algoritmos de reversão.
Imagine uma pilha de pratos: o último prato colocado é o primeiro a ser retirado. Um histórico de alterações segue o mesmo princípio, a última alteração geralmente é a primeira a ser mostrada.

Melhor para: undo/redo, call stack, DFS, qualquer fluxo “último entra, primeiro sai”.
Quando não usar: quando a ordem de chegada importa mais que a ordem inversa — aí é fila.
Aprofundar: Implementando Pilhas
Filas (queues): FIFO quando a ordem de chegada manda
Filas seguem a lógica FIFO (First In, First Out), ou seja, o primeiro a entrar é o primeiro a sair. São perfeitas para situações onde a ordem importa, como em gerenciamento de tarefas ou execução sequencial de processos.
Imagine uma fila de pessoas esperando ser atendidas: quem chega primeiro, é atendido primeiro.
Na programação, isso se aplica a várias operações, como processar etapas de uma compra, onde cada passo segue uma ordem específica (verificação de estoque, criação do pedido, etc.). Filas garantem que tudo aconteça na sequência correta, organizando tarefas complexas de forma eficiente.

Melhor para: filas de jobs, BFS, processamento em ordem de chegada.
Quando não usar: quando só o item mais recente importa — pilha resolve com menos conceito.
Aprofundar: Implementando Filas
Árvores: hierarquia sem ser o bicho de sete cabeças
Árvores organizam dados em hierarquia: cada nó pode ter filhos. Pensa nas pastas do seu SO — pasta dentro de pasta — é árvore na prática, mesmo quando a UI não mostra o código.

Melhor para: DOM, pastas, taxonomias, qualquer relação pai/filho.
Quando não usar: quando a relação entre nós não é hierárquica (A conecta B sem “pai único”) — aí entra grafo.
Aprofundar: Implementando Árvores
Grafos: rotas, redes e relações sem hierarquia fixa
Grafos conectam nós de forma flexível — sem exigir um único “pai” como na árvore.
Isso permite representar relações complexas, como as rotas em um mapa. Imagine usar um app de navegação para ir do ponto A ao B: existem muitos caminhos possíveis, cada um com suas ruas e direções.
Nos grafos, é assim que os nós se relacionam, permitindo explorar diversas conexões até encontrar a informação desejada ou o caminho ideal.

Melhor para: redes sociais, mapas, dependências entre serviços, qualquer “quem conecta com quem”.
Quando não usar: problema simples linear ou hierárquico — árvore ou array costuma ser mais simples de manter.
Aprofundar: Implementando Grafos
Hash tables: lookup rápido por chave
As Hash Tables são estruturas que organizam dados de maneira eficiente, funcionando com um sistema de chave-valor, similar aos Maps.
A grande sacada é que, ao invés de buscar diretamente pela chave, usamos uma função de hash que transforma essa chave em um índice de um array onde o valor está armazenado. Isso pode parecer um passo extra, mas torna a busca super rápida. O truque está em lidar bem com situações onde duas chaves diferentes resultam no mesmo índice, isso é conhecido como colisão.
Graças à rapidez na localização dos dados, as Hash Tables são excelentes para acessar rapidamente informações e manter dados onde a unicidade é crucial.

Se a gente precisa analisar um texto e contar quantas vezes determinada palavra ou número é mencionado no texto, podemos criar uma Hash Table e para cada palavra ou número que queremos contar, nós mapeamos um contador e contamos a frequência que os elementos aparecem no texto.
Melhor para: cache, contagem de frequência, lookup O(1) médio por chave.
Quando não usar: quando precisa de ordem entre chaves — BST ou array ordenado entram na jogada.
Aprofundar: Implementando Hash Tables
Heaps: o topo da fila sempre visível
Heaps são Árvores. O que acontece é que Heaps são um tipo especial de árvores utilizadas para manter elementos organizados de uma certa maneira, facilitando operações como ordenação e gestão de filas de prioridade.
Imagina uma árvore que sempre sabe quem deve estar no topo (no topo da árvore) com base em certas regras — é assim que funcionam os heaps. Eles são super úteis em várias situações, como distribuir tarefas entre servidores ou até recomendar produtos online.
Por exemplo, após comprar algo num site, os produtos recomendados que aparecem podem estar sendo ordenados usando um heap. Essa ordenação se baseia em critérios como popularidade ou relevância, garantindo que a pessoa veja primeiro o que mais interessa.

Heaps são muito conhecidos pela classificação de Max Heap e Min Heap. Outro ponto legal sobre os Heaps é que eles podem ajudar a implementar as Filas de Prioridade, que vou resumir a seguir!
Melhor para: fila de prioridade, “próximo item mais urgente”, ordenação parcial.
Quando não usar: quando precisa buscar um valor arbitrário no meio — hash table ou BST.
Aprofundar: Implementando Heaps
Priority queues: prioridade antes da ordem de chegada
Combinando características de filas e heaps as Filas de Prioridade são estruturas que organizam elementos não pela ordem de chegada, mas sim pela prioridade de cada um. Imagina uma mistura de filas comuns e heaps, onde o que importa é quão importante é um item, e não quando ele chegou.
Essa característica faz com que itens mais prioritários sejam atendidos primeiro, independentemente de sua posição na fila.
Isso é super útil em várias situações, como sistemas operacionais que precisam decidir qual processo executar primeiro, sistemas de recomendação que mostram conteúdos mais relevantes, ou até em bancos de dados para priorizar consultas. Basicamente, é como ter um atalho sempre que algo realmente importante precisa ser feito.

Melhor para: scheduler de SO, fila de tarefas críticas, recomendação por score.
Quando não usar: FIFO puro basta — fila comum é mais simples.
Aprofundar: Implementando Filas de Prioridade
Maps e Sets: chave-valor e elementos únicos
Mapas (Maps) armazenam pares de chave-valor, ou seja, cada bloco de informação tem uma chave e um valor que você determina. Os maps lembram muito as Hash Tables, mas aqui não temos uma hash que aponta para um index e dai encontramos o valor, aqui no Map temos uma chave que aponta diretamente para o valor.

Enquanto “conjuntos” (é meio estranho falar “conjuntos” então vamos usar “Sets”) os Sets não tem uma estrutura de chave-valor igual ao map, em questão de estrutura os sets se assemelham aos Arrays porém com uma regra especial, os sets tem elementos únicos, ou seja, se você tentar incluir um dado que já exista em um Set, você não vai incluir, o Set não vai ter registros “duplicados”.

Maps são muito usados em sistemas de cache, e também por exemplo em mapeamento de dados pra requisições, onde um campo X precisa ser mapeado para um campo Y em uma chamada de API para outros serviços.
Sets são muito usados quando queremos remover itens duplicados de Arrays, ou um outro exemplo seria entrada de dados em uma API, se você tem uma API que recebe um JSON por exemplo, você consegue com um Set garantir que esse JSON não venha com campos duplicados.
Melhor para: Map em cache e mapeamento de campos; Set pra deduplicar.
Quando não usar: precisa só de array ordenado simples — Map/Set podem ser overkill.
Aprofundar: Implementando Maps e Sets
BST: busca binária organizada em árvore
BST (binary search tree): para cada nó, esquerda menor, direita maior. Regra simples, implementação que exige cuidado com balanceamento em produção.

Melhor para: conjuntos ordenados, busca logarítmica quando a árvore está equilibrada.
Quando não usar: dados já vêm hasháveis e ordem não importa — hash table costuma ser mais direta.
Aprofundar: Implementando Árvores de Busca Binária
Trie: autocomplete e busca por prefixo
Trie é árvore focada em texto: cada nó costuma representar um caractere; o caminho forma a palavra.

Um bom exemplo é autocomplete: digita A e o sistema sugere palavras que começam com esse prefixo.
Melhor para: dicionários, autocomplete, IP routing por prefixo.
Quando não usar: poucas strings curtas — hash table ou array ordenado resolvem mais rápido de implementar.
Aprofundar: Implementando Tries
Menor caminho (Dijkstra): GPS e rotas no grafo
Aqui não é um “tipo novo” de grafo — são algoritmos (Dijkstra, Bellman-Ford) que percorrem o grafo buscando o caminho de menor custo entre A e B.

Não é algo que você implementa todo dia — a menos que trabalhe com roteamento, logística ou redes.
Melhor para: navegação, logística, redes com peso nas arestas.
Quando não usar: grafo pequeno ou custo uniforme — BFS às vezes basta.
Aprofundar: Algoritmos de grafos (menor caminho)
Algoritmos de ordenação: BubbleSort, QuickSort e MergeSort
Quando você tem um array e precisa ordená-lo, existem diversos métodos para fazer isso. Embora linguagens de programação já venham com funções de ordenação, às vezes queremos explorar outras formas para entender suas eficiências ou simples curiosidade. Vamos falar sobre três algoritmos de ordenação populares, explicando de maneira simples:
BubbleSort: Um dos métodos mais básicos, onde você compara itens adjacentes e os troca se estiverem na ordem errada. É como percorrer o array, trocando pares até tudo estar ordenado. QuickSort: Rápido e eficiente, usa a técnica de dividir para conquistar. Escolhe um “pivot” e organiza o array de modo que elementos menores fiquem antes e maiores depois, repetindo o processo nos sub-arrays. MergeSort: Também segue a lógica de dividir para conquistar, mas divide o array sempre ao meio. Ordena cada metade e depois as combina de forma ordenada. É um processo de dividir, ordenar e juntar. Veja um exemplo do merge-sort:

"Tá Jon, ainda uso
.sort()e pronto. Preciso saber disso?"
Em entrevista e em debug de performance, sim — saber que sort do JS é estável desde ES10 e que engines misturam algoritmos ajuda. Em produção, .sort() resolve a maior parte.
Melhor para: entender tradeoffs em entrevistas e escolher estrutura antes de ordenar milhões de linhas.
Quando não usar: reimplementar sort na mão em produto — use o nativo, salvo requisito muito específico.
Aprofundar: Ordenando arrays
Busca binária: só funciona em lista ordenada
Na busca comum, vamos de um a um em um array. Já na busca binária ela compara o elemento que estamos buscando com o meio do array, e divide o array pela metade. Repetimos esse processo na metade metade do array promissora até achar o item ou acabar as opções. Soa complexo, mas é simples. O ponto chave aqui é que a busca é eficaz em listas ordenadas, só assim ela agiliza a procura.

Dicionário ordenado por palavra é o exemplo clássico: a cada passo você elimina metade do espaço de busca.
Melhor para: coleções grandes já ordenadas, tabelas de lookup em memória.
Quando não usar: lista desordenada ou que muda o tempo todo — ordenar + buscar pode custar mais que um scan ou um Map.
Aprofundar: Implementando busca binária
Como combinar: array + hash + fila no mesmo sistema
Sabe aquele parafuso que não aperta com faca? Na prática você mistura estruturas: array pra lista na tela, Map pra cache por id, fila pra jobs assíncronos. O mapa deste post é pra você nomear a ferramenta certa — os episódios seguintes mostram o código.
O que ficou de fora deste resumo
- Deque, skip list, bloom filter — úteis, mas fora do escopo “mais usados no dia a dia em JS”.
- Estruturas em disco (B-tree de banco) — outro capítulo; aqui focamos em memória com Node.js.
- Big-O formal completo — citamos complexidade na tabela, mas não é curso de análise de algoritmos.
Se faltar algo que você usa todo dia e não está na lista, comenta — vale virar episódio ou nota no próximo update.
TL;DR — Referência rápida das estruturas de dados
| Estrutura | Acesso | Inserção | Remoção | Caso de uso típico |
|---|---|---|---|---|
| Array | O(1) | O(n) | O(n) | Listas de tamanho fixo, acesso por índice |
| Linked List | O(n) | O(1) | O(1) | Histórico de navegador, inserções frequentes |
| Stack | O(n) | O(1) | O(1) | Undo/redo, call stack, DFS |
| Queue | O(n) | O(1) | O(1) | Filas de processamento, BFS |
| Hash Table | O(1) médio | O(1) médio | O(1) médio | Cache, lookup rápido por chave |
| Tree / BST | O(log n) | O(log n) | O(log n) | Hierarquias, busca ordenada |
| Graph | — | O(1) | O(1) | Redes sociais, GPS, rotas |
| Heap | O(n) | O(log n) | O(log n) | Filas de prioridade, algoritmos de ordenação |
| Trie | O(m) | O(m) | O(m) | Autocomplete, dicionários |
| Binary Search | O(log n) | — | — | Busca em listas ordenadas |
Próximos passos
Esse post dá o panorama — cada uma dessas estruturas tem um post de implementação completa nessa série. Comece pelo que você usa mais:
- Implementando Arrays com Node.js e JavaScript
- Implementando Listas Ligadas com Node.js e JavaScript
- Implementando Pilhas com Node.js e JavaScript
- Implementando Filas com Node.js e JavaScript
- Implementando Árvores com Node.js e JavaScript
Antes de fechar
Qual estrutura você mais usa no trabalho — array, Map, ou fila? Se viu erro no texto ou acha que faltou uma estrutura óbvia, comenta que a gente ajusta e compartilha o conhecimento.
Inscreva-se no Ledger da Engenharia
Receba notas de arquitetura e performance na sua caixa de entrada. Mesma lista do convite—inscreva-se aqui quando quiser.
Artigos relacionados
Implementando Array com NodeJS e Javascript
Arrays em JavaScript/Node.js: métodos essenciais, imutabilidade e quando preferir array em vez de outras estruturas. Guia com código.
Ler publicação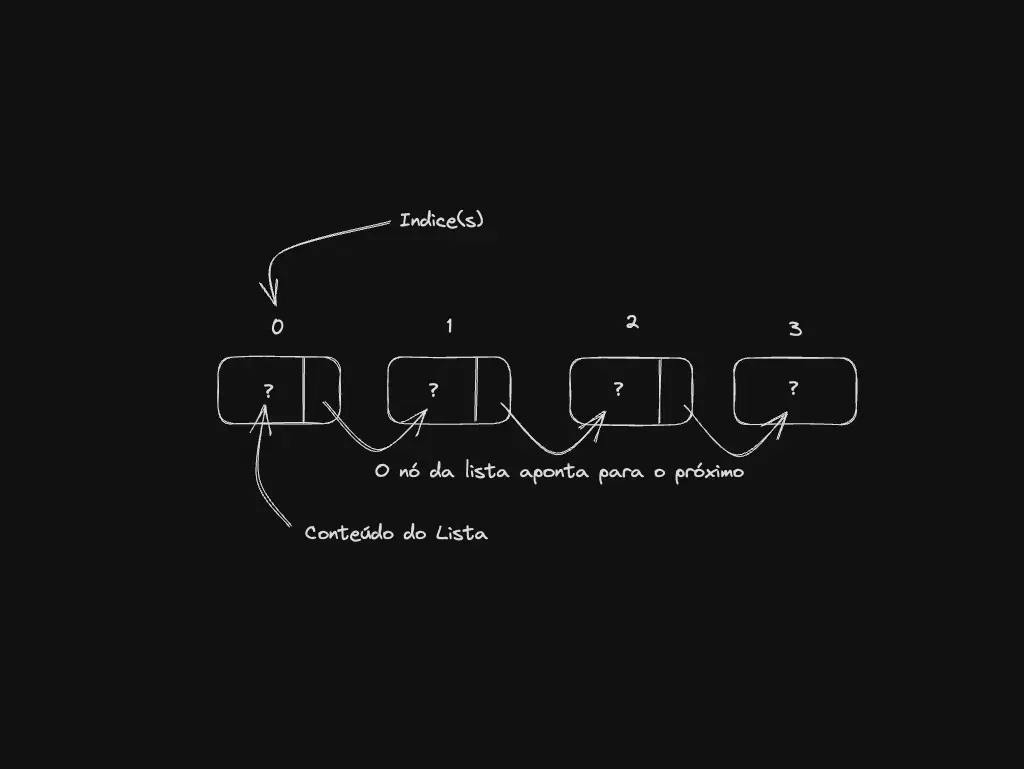
Implementando Lista Ligada (Linked List) com NodeJS e Javascript
Lista ligada em JavaScript do zero: nós, inserção, remoção e quando ela vence o array. Tutorial prático e direto com Node.js.
Ler publicação