jonathanjuliani
Data Structures and Algorithms - A Summary of The Most Used Ones
Practical overview of the data structures and algorithms you use most in JavaScript/Node.js — with examples and links to go deeper.

Picking the wrong structure for the job—array when you needed a hash table, linear search on data that was already sorted—usually becomes a slow bug that only shows up at scale. This post is the map: fifteen structures and algorithms you will see most often in JavaScript/Node.js, with criteria for when to use each and a link to the implementation episode.
What you'll learn:
- What arrays, linked lists, stacks, queues, trees, and graphs are for
- Hash tables, heaps, priority queues, maps, and sets — where each shines
- Binary search, BSTs, tries, and graph algorithms — when they apply
- Sorting algorithms (bubble, merge, quick) — how to tell them apart
- Real day-to-day scenarios for each structure
Prerequisites: comfortable with basic programming — variables, functions, and arrays. No prior data structures course required.
How this list was built: structures that show up in interviews, production Node.js code, and the rest of this series — with a minimal example and a link to go deeper. Not an academic catalogue.
Arrays: the structure you already use every day
Arrays store elements in sequence and give you fast access by index. To-do lists, shopping carts, and API result lists are arrays in practice—even when the UI does not say “array.”
Best for: index access, sequential iteration, in-memory lists where you are not constantly inserting in the middle.
When not to use: frequent insertions or removals in the middle of very large collections — a linked list often wins.
Go deeper: Implementing Arrays with Node.js and JavaScript
Linked lists: flexibility without shifting the whole array
Each node holds data and a pointer to the next node. Doubly linked lists also point backward, which makes undo-style navigation easier. Browser history is the classic mental model: each page is a node, and you move forward and back along the chain.
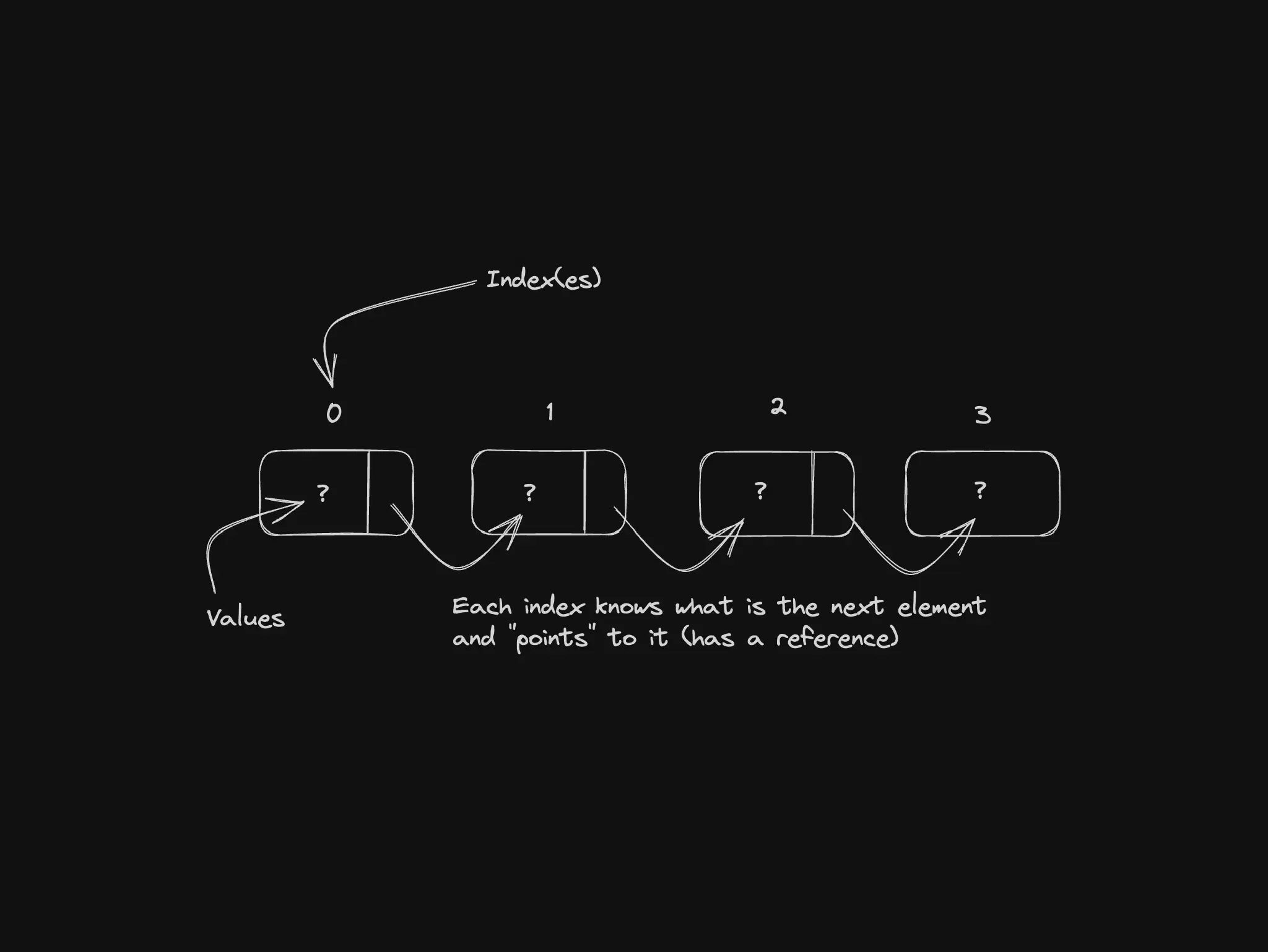
Doubly linked list:
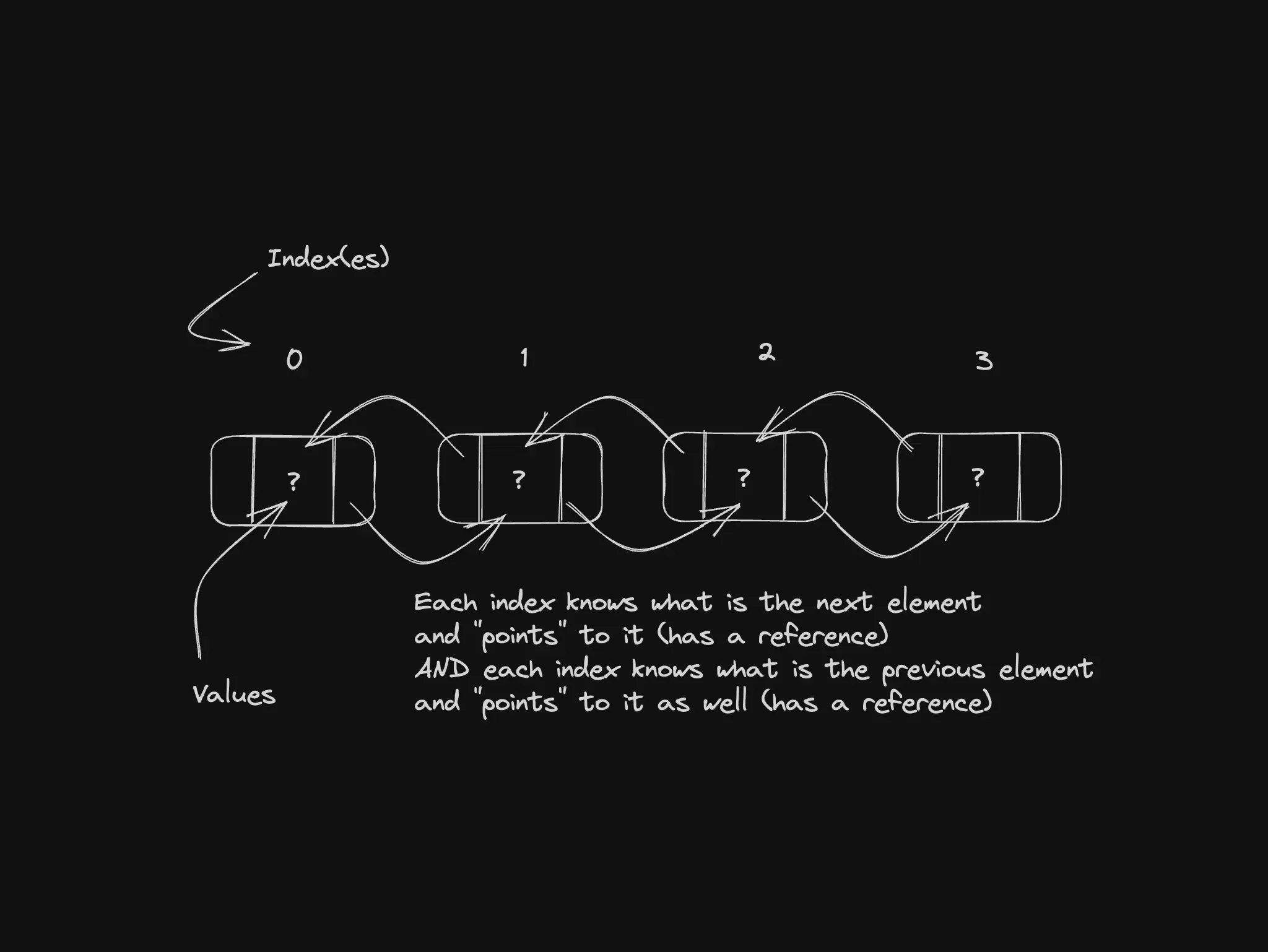
Best for: browser history, edit stacks, insert/remove in the middle without shifting the entire array.
When not to use: when you need O(1) random access by index — arrays win.
Go deeper: Implementing Linked Lists
Stacks (LIFO): undo and the call stack
Stacks follow last-in, first-out (LIFO). The most recent item is the first one you pop—like a stack of plates or an undo stack.
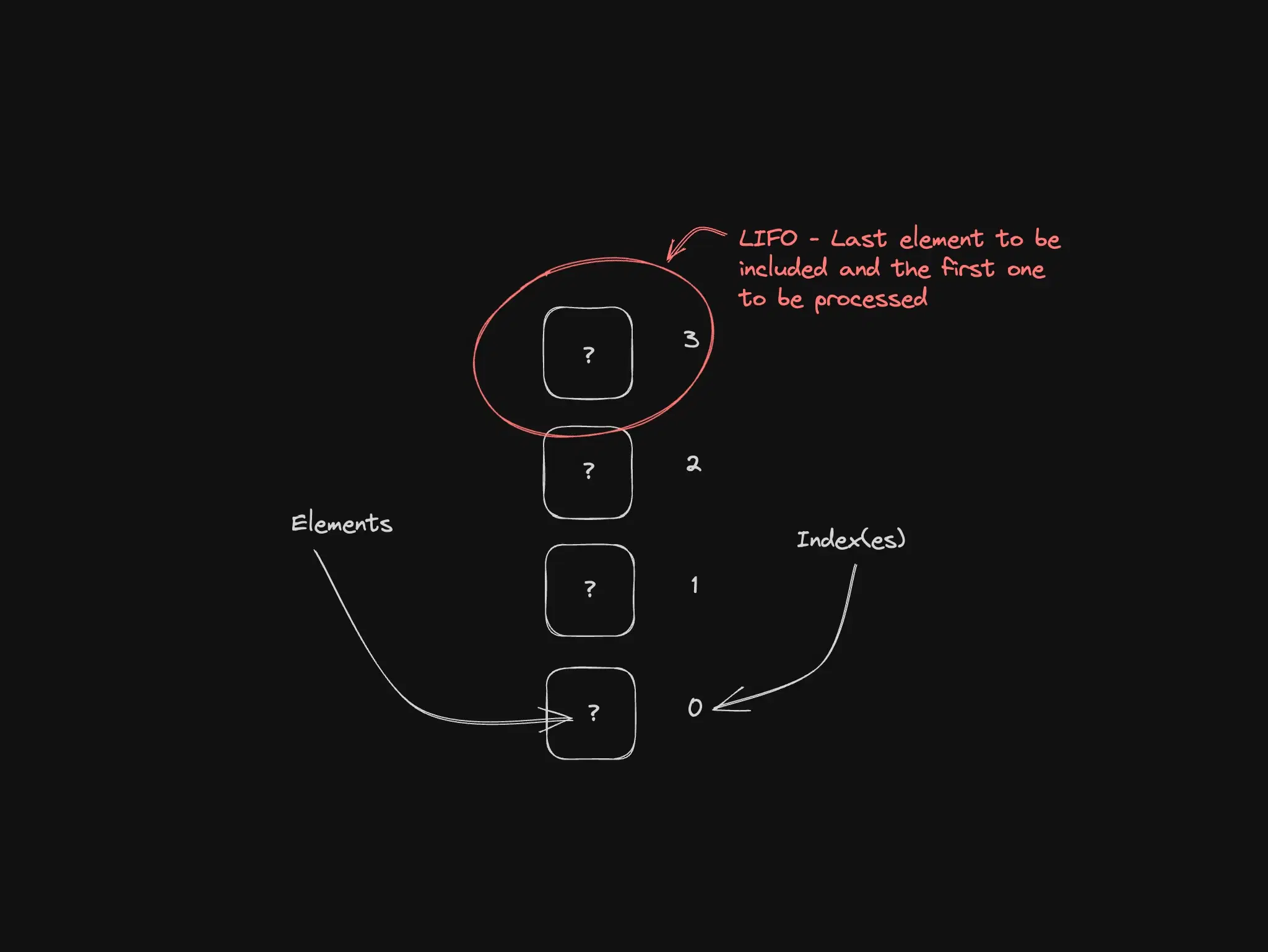
Best for: undo/redo, the call stack, DFS, any flow where the last item in must be the first out.
When not to use: when arrival order matters more than reverse order — use a queue.
Go deeper: Implementing Stacks
Queues (FIFO): when arrival order wins
Queues follow first-in, first-out (FIFO). Job runners, BFS, and checkout pipelines all depend on “who got here first gets served first.”
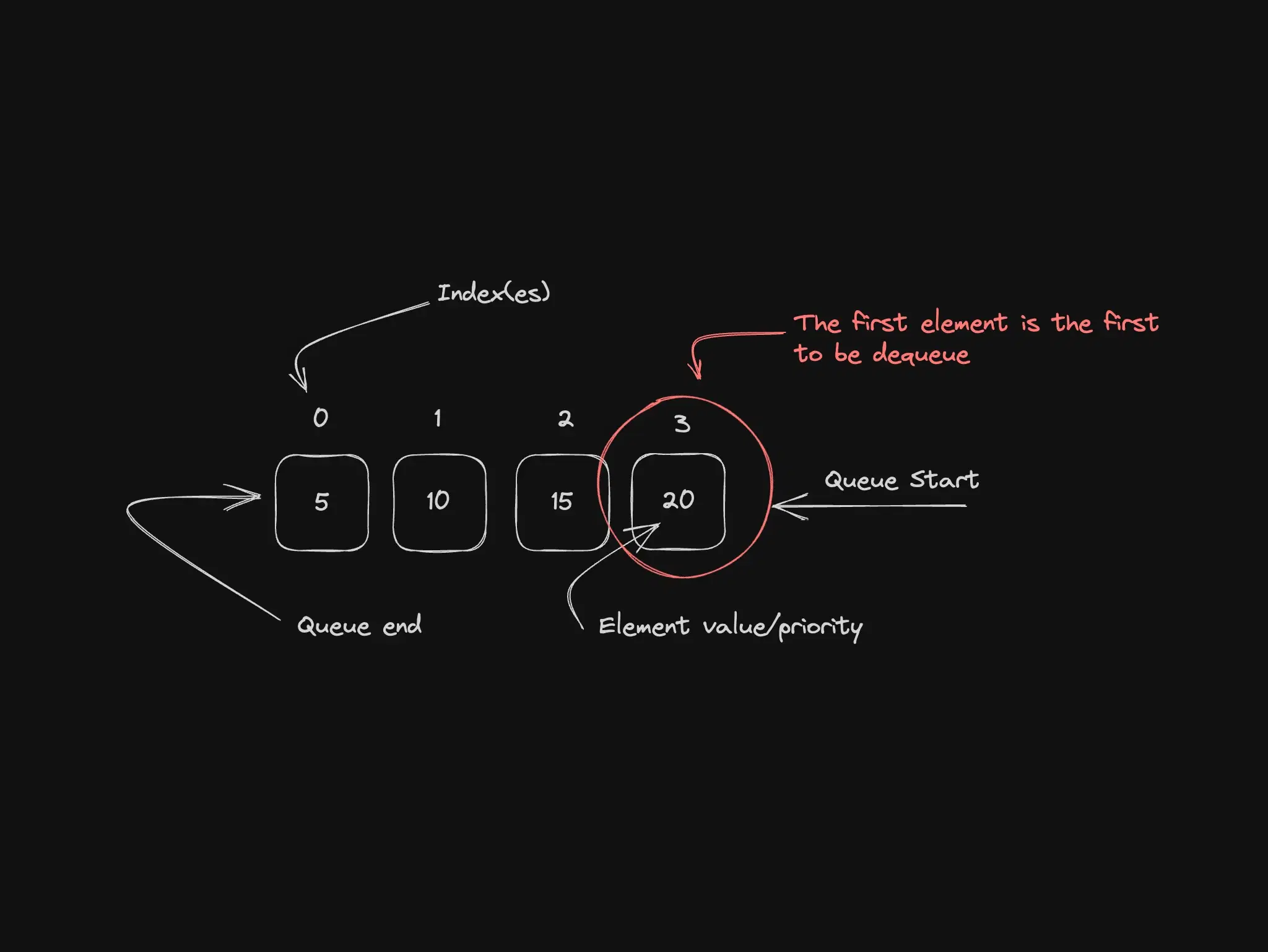
Best for: job queues, BFS, processing in arrival order.
When not to use: when only the latest item matters — a stack is simpler.
Go deeper: Implementing Queues
Trees: hierarchy without the seven-headed monster
Each node can have children. Folders on disk, the DOM, and org charts are trees even when the UI hides the code.
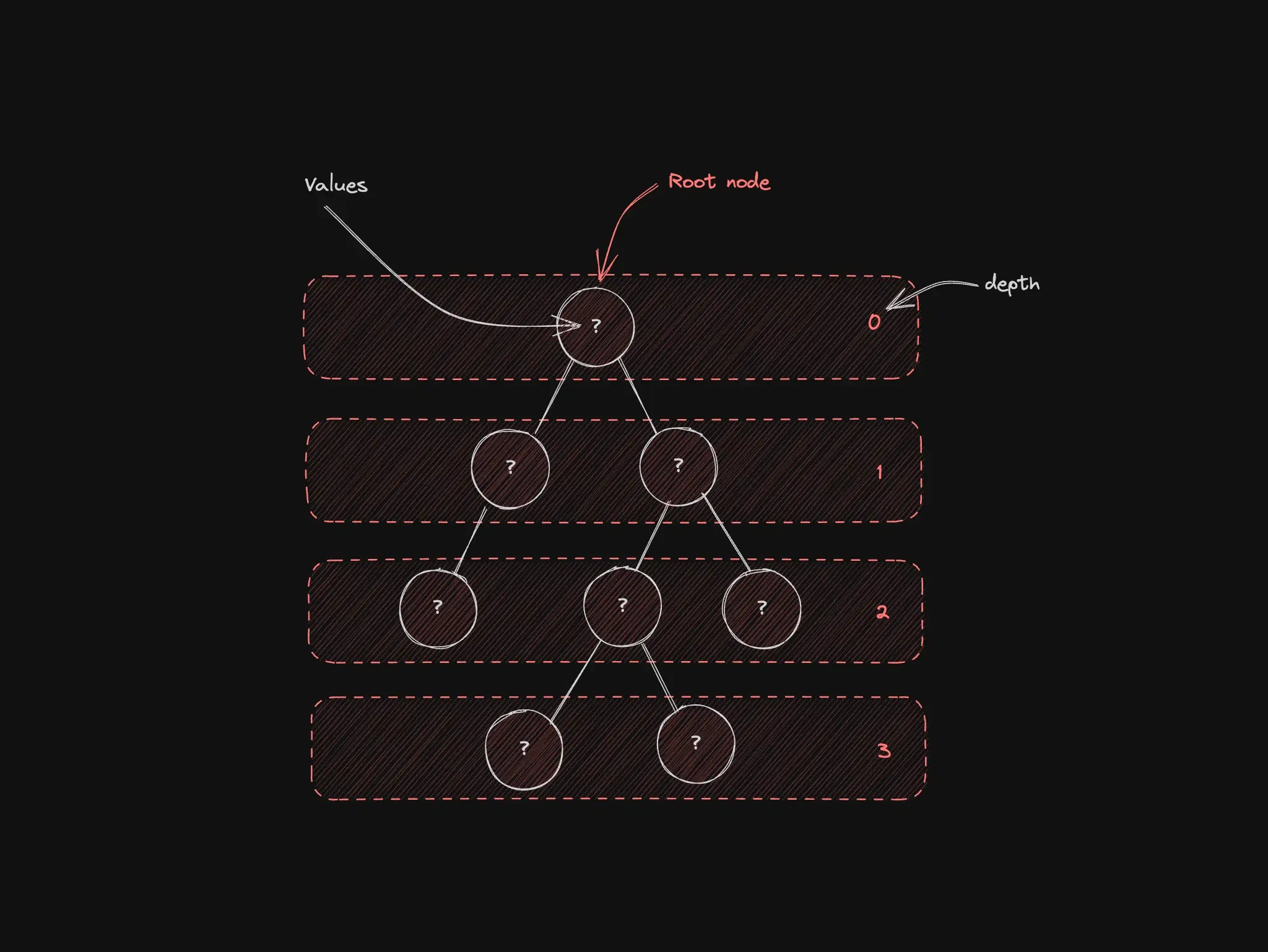
Best for: DOM, directories, taxonomies, any parent/child relationship.
When not to use: when relationships are not hierarchical (A connects to B without a single parent) — that is a graph.
Go deeper: Implementing Trees
Graphs: routes, networks, and non-hierarchical links
Nodes connect flexibly—no single parent rule like a tree. Navigation apps explore many paths between A and B; social graphs model “who knows whom.”
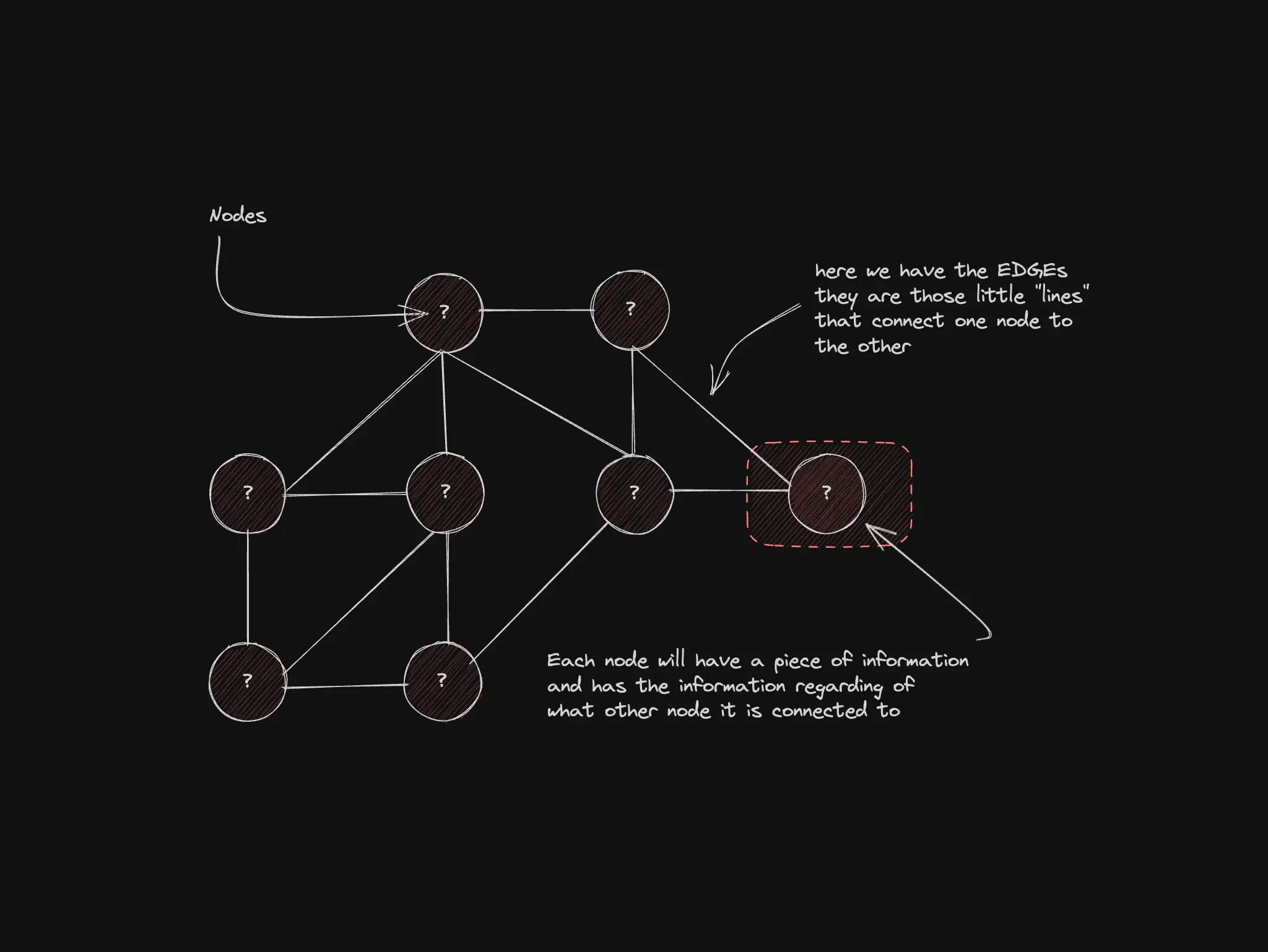
Best for: social networks, maps, service dependencies, any “who connects to whom” model.
When not to use: simple linear or hierarchical problems — trees or arrays are easier to maintain.
Go deeper: Implementing Graphs
Hash tables: fast lookup by key
Key-value storage with a hash function mapping keys to array indices. Collisions are the interesting part; average-case lookup stays O(1). Word-frequency counting in a document is a textbook use case.
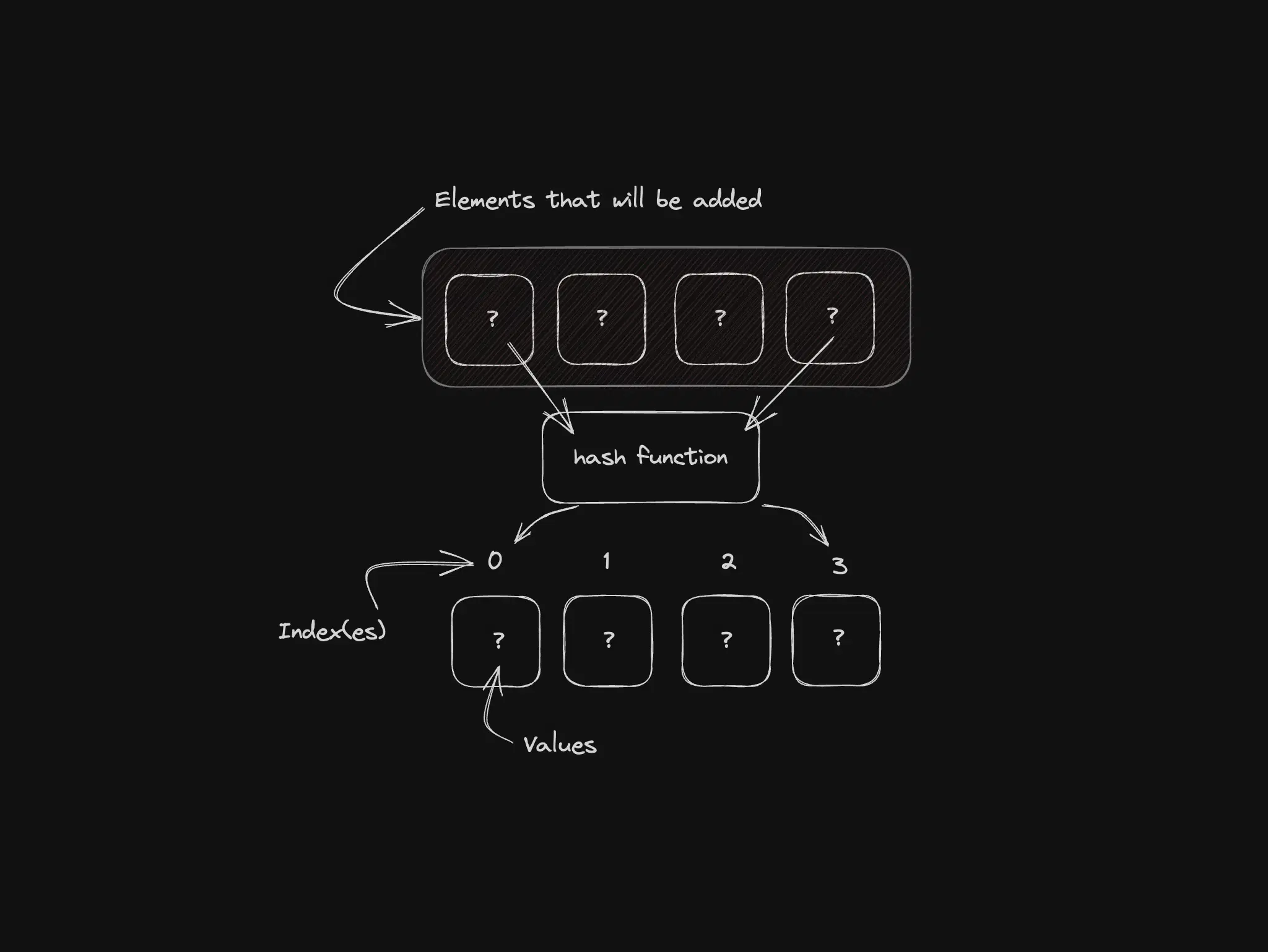
Best for: caches, frequency counts, average O(1) lookup by key.
When not to use: when you need ordered keys — a BST or sorted array fits better.
Go deeper: Implementing Hash Tables
Heaps: always know what is on top
Heaps are specialized trees for partial ordering—max-heap or min-heap—useful for priority scheduling and “show the most relevant item first” (recommendations, task runners).
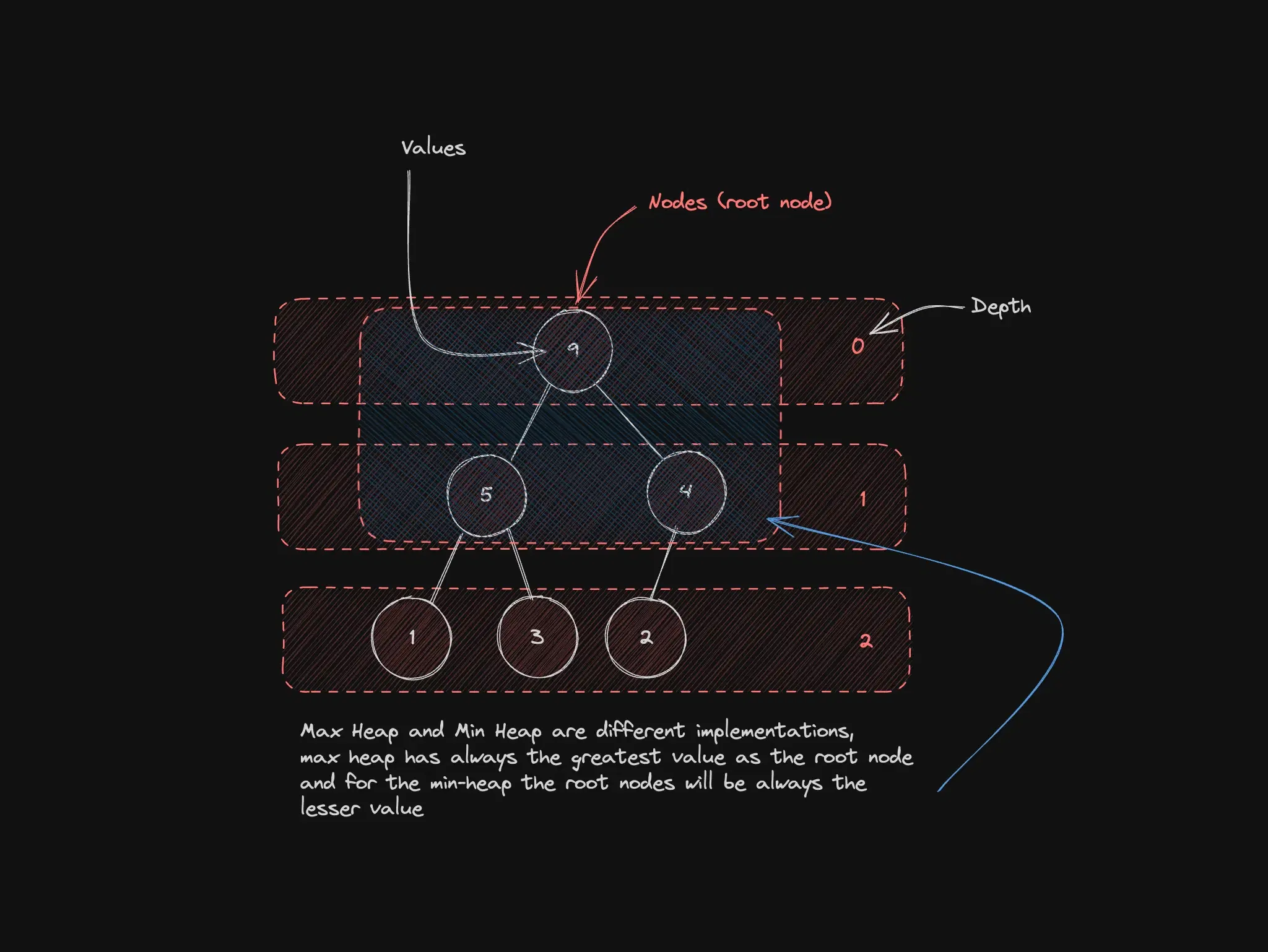
Heaps underpin many priority queue implementations.
Best for: priority queues, “next most urgent item,” partial sorting.
When not to use: arbitrary lookups in the middle — hash tables or BSTs are a better fit.
Go deeper: Implementing Heaps
Priority queues: importance beats arrival time
Items dequeue by priority, not FIFO. OS schedulers, recommendation feeds, and database query prioritization use this pattern.
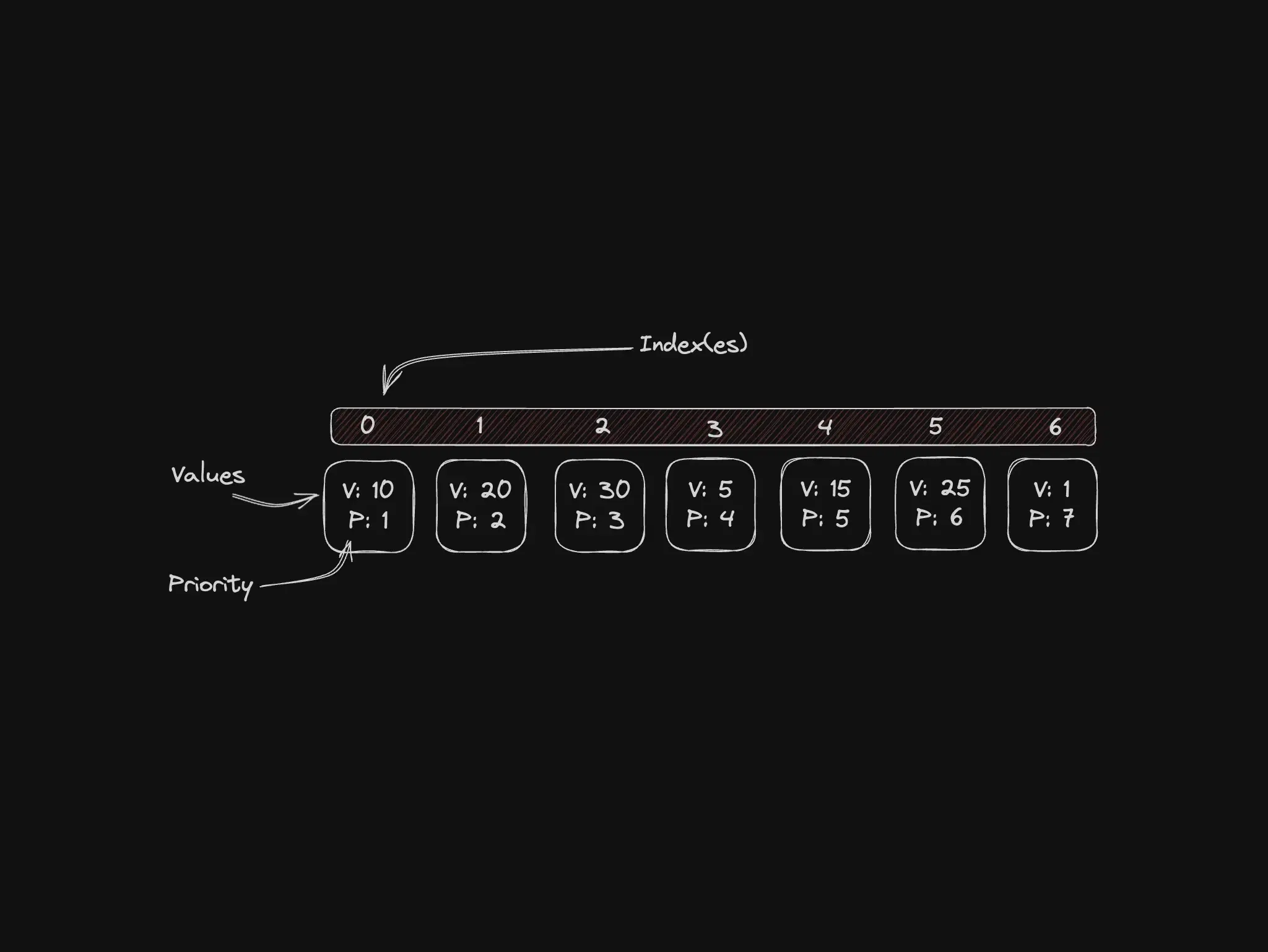
Best for: OS schedulers, critical task queues, scoring-based recommendations.
When not to use: plain FIFO is enough — a regular queue is simpler.
Go deeper: Implementing Priority Queues
Maps and Sets: key-value pairs and unique elements
Map stores key-value pairs with direct key lookup (similar spirit to hash tables, different API). Set keeps unique values—handy for deduplicating arrays or validating JSON field names.
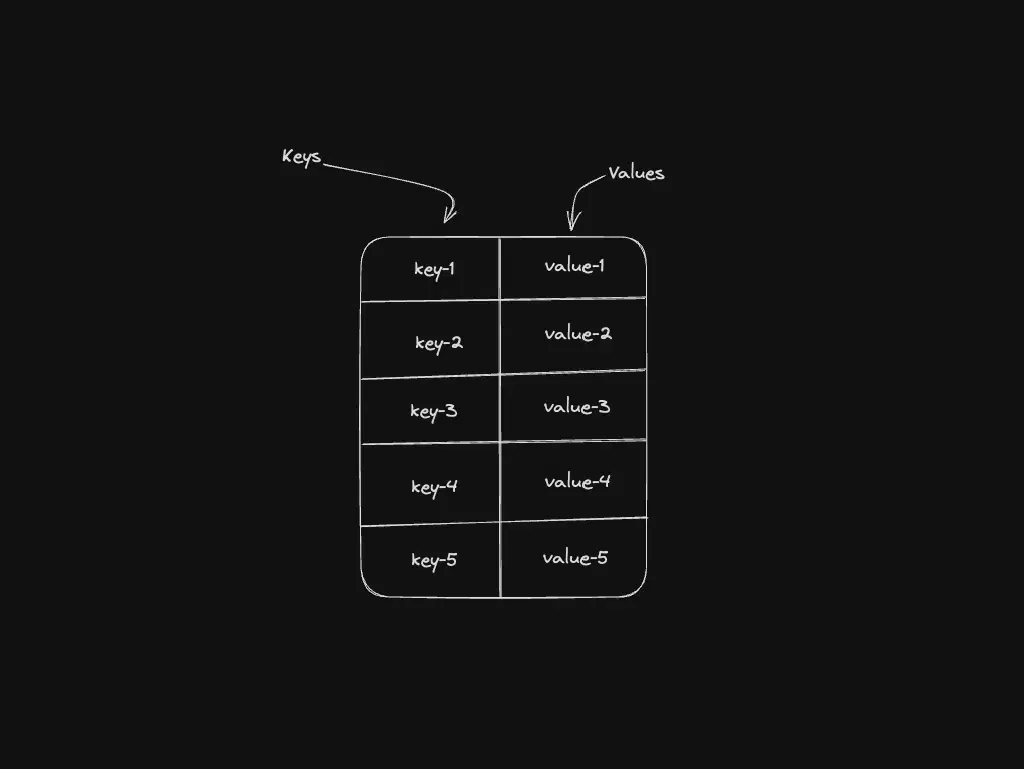
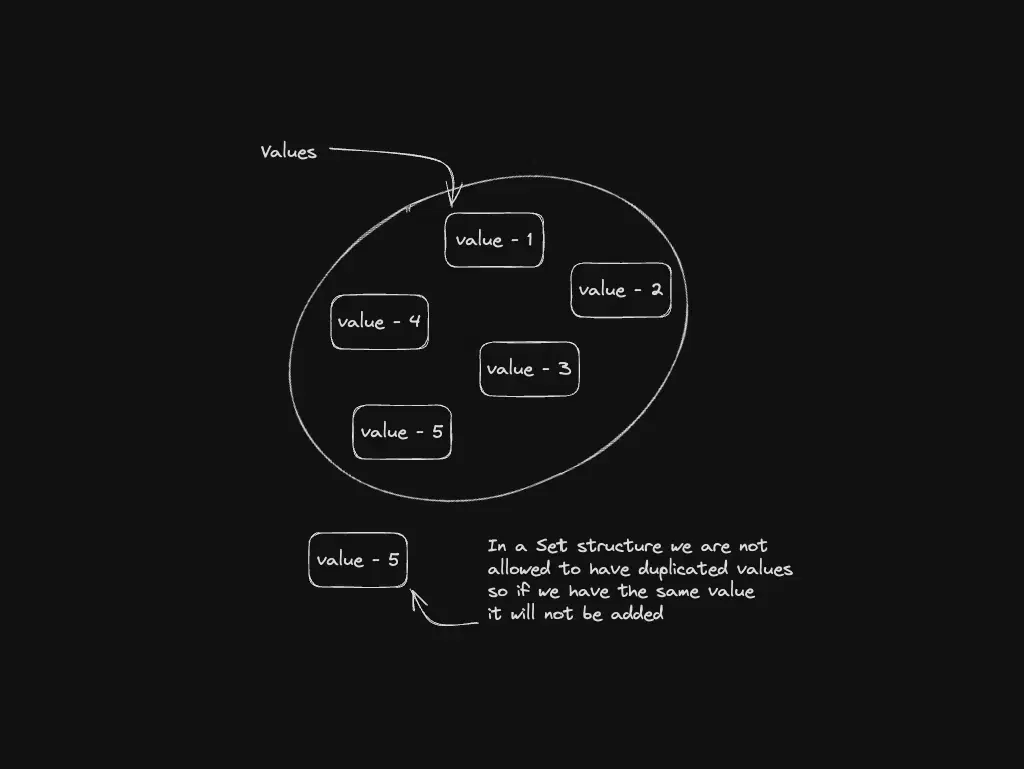
Best for: Map in caches and field mapping; Set for deduplication.
When not to use: a plain sorted array is enough — Map/Set may be overkill.
Go deeper: Implementing Maps and Sets
BST: ordered search in a tree
For each node, left subtree values are smaller and right subtree values are larger. Simple rule; production code still needs balance awareness.
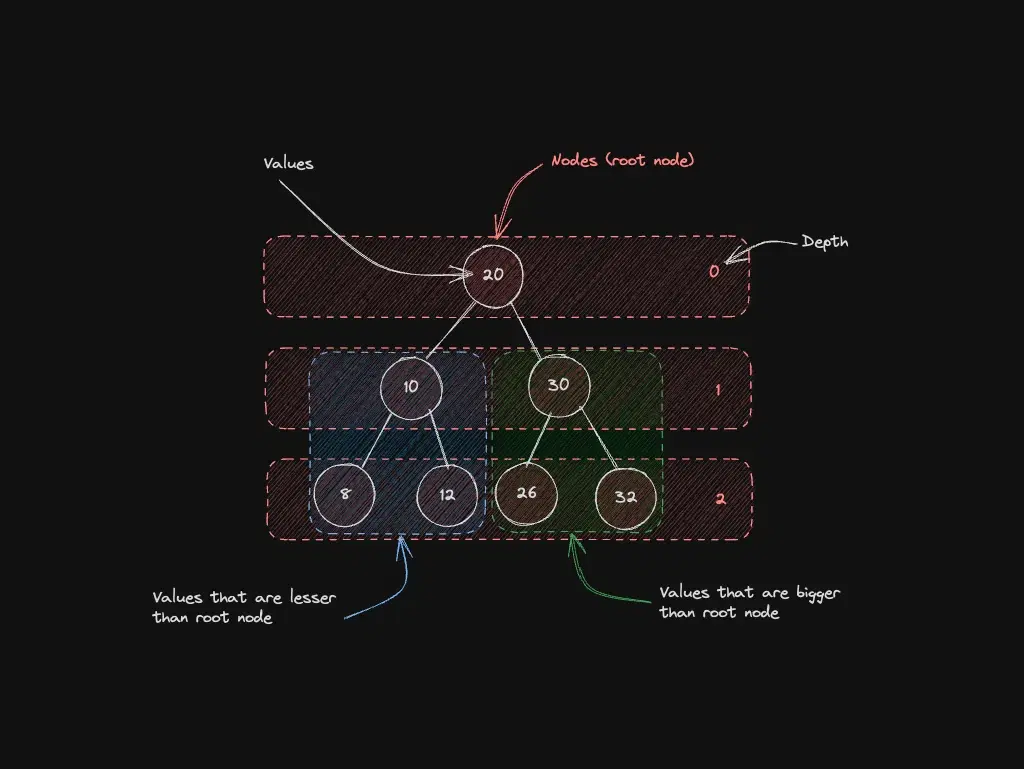
Best for: ordered sets, logarithmic search when the tree stays balanced.
When not to use: keys are hashable and order does not matter — hash tables are often more direct.
Go deeper: Implementing Binary Search Trees
Trie: autocomplete and prefix search
Each node often represents a character; paths spell words. Type A and suggest everything that starts with that prefix.
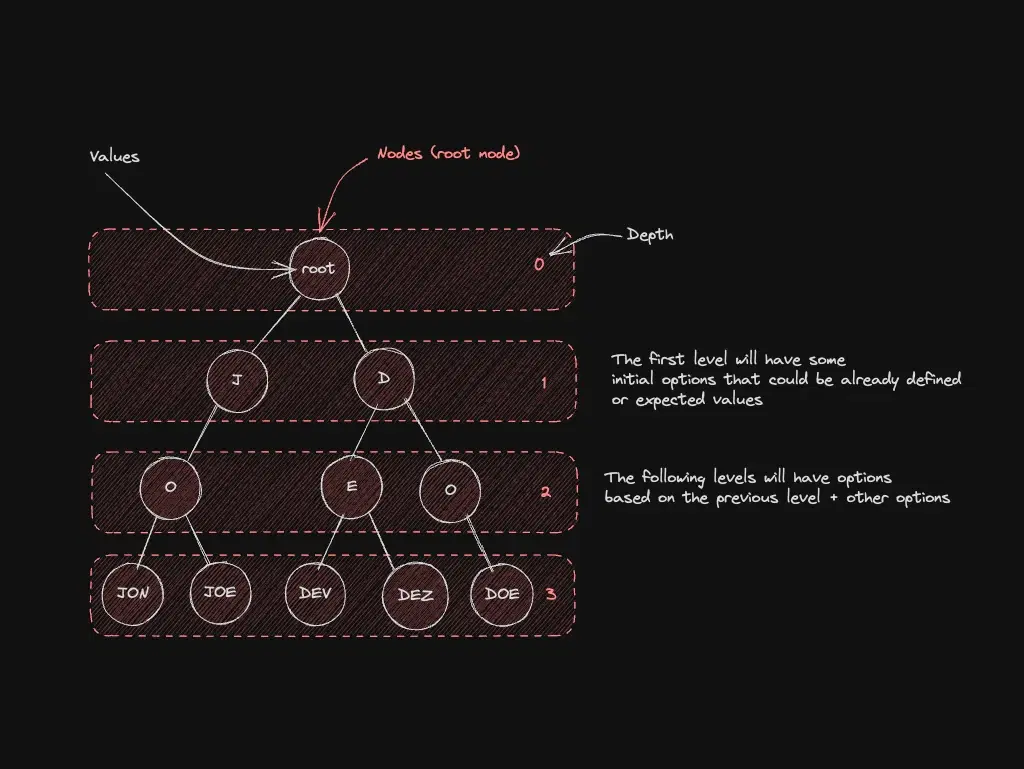
Best for: dictionaries, autocomplete, IP routing by prefix.
When not to use: few short strings — hash tables or sorted arrays are faster to ship.
Go deeper: Implementing Tries
Shortest path (Dijkstra): GPS on a weighted graph
Not a new graph type—algorithms (Dijkstra, Bellman-Ford) that walk edges to minimize cost between A and B.
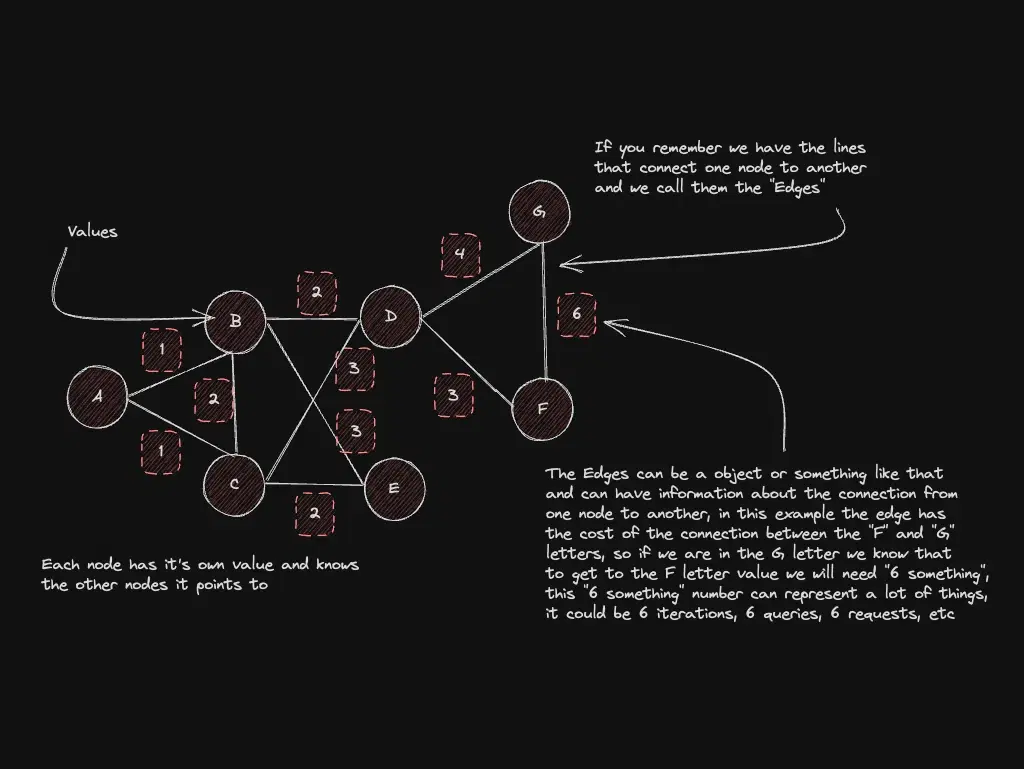
You will not implement this daily unless you work on routing, logistics, or networks.
Best for: navigation, logistics, weighted networks.
When not to use: small graphs or uniform edge cost — BFS is sometimes enough.
Go deeper: Graph algorithms (shortest path)
Sorting algorithms: BubbleSort, QuickSort, and MergeSort
BubbleSort swaps adjacent pairs until sorted. QuickSort partitions around a pivot. MergeSort splits in half, sorts, merges. Engines mix strategies; .sort() in JavaScript is stable since ES10.
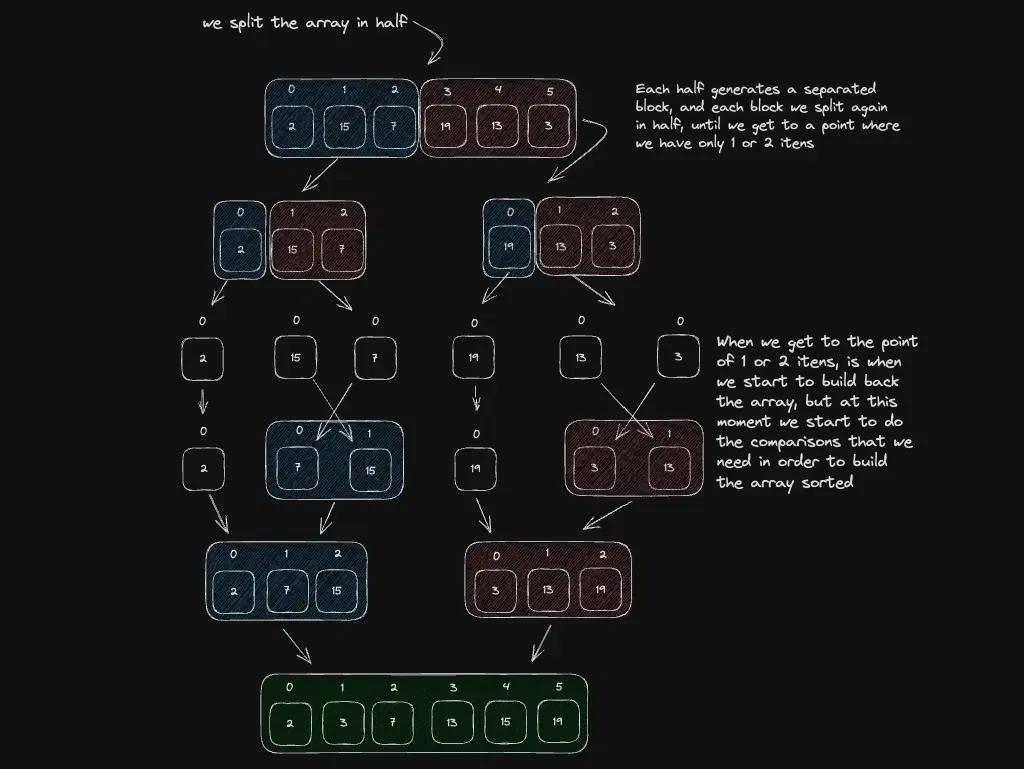
Still using
.sort()and calling it a day? For interviews and performance debugging, knowing the tradeoffs matters. In production, native sort is usually the right call.
Best for: understanding tradeoffs in interviews and before sorting millions of rows.
When not to use: hand-rolling sort in product code — use the built-in unless you have a very specific requirement.
Go deeper: Sorting arrays
Binary search: only on sorted data
Compare with the middle element, discard half, repeat. A sorted dictionary is the classic example—you eliminate half the search space each step.
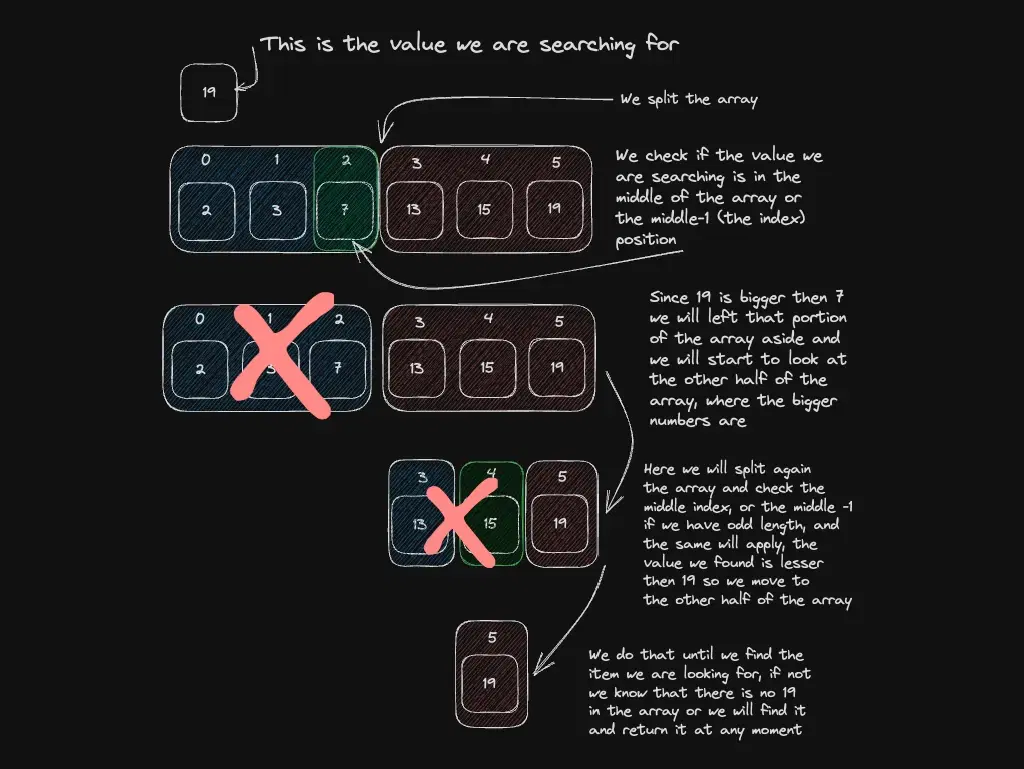
Best for: large sorted collections, in-memory lookup tables.
When not to use: unsorted or constantly mutating lists — sorting plus searching can cost more than a scan or a Map.
Go deeper: Implementing binary search
How they fit together: array + hash + queue in one system
Wrong tool, wrong problem—like using a knife as a screwdriver. In production you mix structures: arrays for UI lists, Map for cache by id, queues for async jobs. This post names the tool; the series shows the code.
What's deliberately out of scope
- Deque, skip list, bloom filter — useful, but outside “most used day to day in JS”.
- On-disk structures (B-trees in databases) — different chapter; here we stay in memory with Node.js.
- Formal big-O proofs — complexity appears in the table, but this is not an algorithms theory course.
If something you use daily is missing, comment — it may deserve an episode or a follow-up note.
TL;DR — Data structures quick reference
| Structure | Access | Insert | Delete | Typical use case |
|---|---|---|---|---|
| Array | O(1) | O(n) | O(n) | Index access, sequential iteration |
| Linked List | O(n) | O(1) | O(1) | Frequent insert/remove in the middle |
| Stack | O(n) | O(1) | O(1) | Undo/redo, call stack, DFS |
| Queue | O(n) | O(1) | O(1) | Job queues, BFS |
| Hash Table | O(1) avg | O(1) avg | O(1) avg | Cache, key lookup |
| Tree / BST | O(log n) | O(log n) | O(log n) | Hierarchies, ordered search |
| Graph | — | O(1) | O(1) | Social graphs, routing |
| Heap | O(n) | O(log n) | O(log n) | Priority queues |
| Trie | O(m) | O(m) | O(m) | Autocomplete, prefixes |
| Binary Search | O(log n) | — | — | Sorted collections |
Next steps
This post is the overview — each structure has a full implementation episode. Start with what you use most:
- Implementing Arrays
- Implementing Linked Lists
- Implementing Stacks
- Implementing Queues
- Implementing Trees
Before you go
Which structure do you reach for most at work? If something in this post is wrong or an obvious tool is missing, leave a comment and we will fix it together.
Subscribe to the Engineering Ledger
Get architecture and performance notes in your inbox. Same list as the timed prompt—subscribe here anytime.
Related articles

Implementing Arrays with NodeJS and Javascript
JavaScript arrays in Node.js: essential methods, immutability patterns, and when an array beats other structures. Hands-on guide.
Read story
Implementing Linked-Lists with NodeJS and Javascript
Linked lists in JavaScript from scratch: nodes, insert/remove, and when they beat arrays. Practical Node.js tutorial with examples.
Read story